Recently, I’ve read the book «CUDA Programming: A Developer’s Guide to Parallel Computing with GPUs». In the introduction, Shane Cook analyses the history of computation and the development of computation solutions.
I would divide the narration into four parts:

In 1945, John von Neumann, during his work on ENIAC (Electronic Numerical Integrator and Computer), described the design of computer architecture, which lies as a basis for all computing architectures we have today, CPU and GPU. The main idea is to fetch the processor instructions from some storing device and execute them by the computation unit. Starting from that point, a computing device was born, and the race to reach computation limits, the number of floating-point operations per second, to be precise, has been started.
The developers of early CPUs (Central Processing Units), noticed many bottlenecks: the frequency of CPU clocks should grow to fetch processor commands fast enough, and the ratio of clock speed to memory limits the overall operation speed of a device.
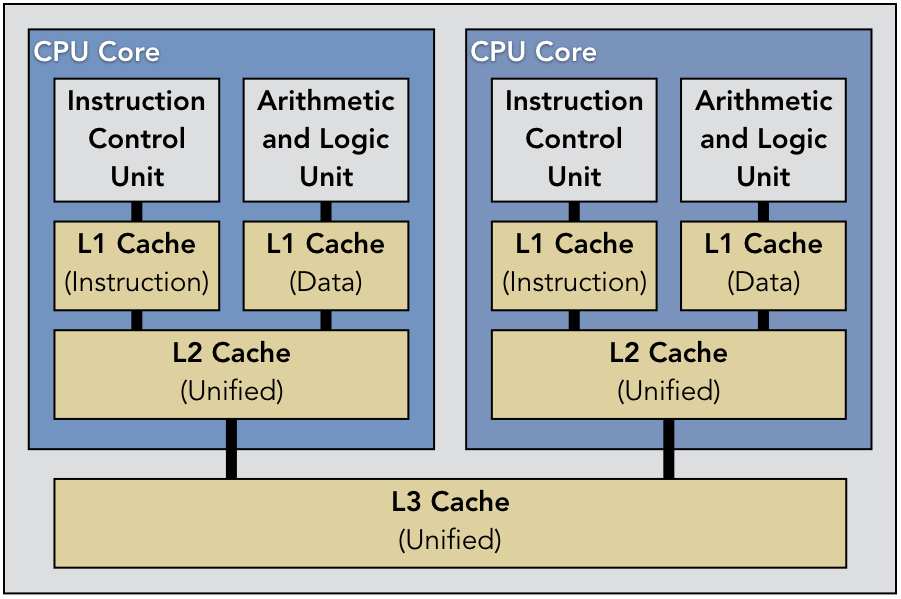
Figure on the left shows the architecture of a single-core processing unit with multiple levels of caching to increase local throughput for some «repeated» operations. This is the key improvement which related to the topic of our course directly.
The cache was born because it appeared to be inefficient, running the same instruction when only data is changed. The same could be said about data, with the difference only in the instructions. The combination of performance improvements we know as 1, 2, and 3 cache levels.
At first, the developers of processors relied on CPU frequency as the main performance metric. Gordon Moore, one of the founders of Intel, made an observation which we know as Moore’s law that says «The number of transistors doubles every two years».
![]()
But history has proven that it’s an incorrect, or not entirely correct, prediction. The clock rate limit is around 4 GHz. As the number of transistors grows, so does the physical size of the silicon used to make the processors. The larger the chip, the more losses it experiences and complicates the manufacturing process. An increase in the clock rate increases power consumption. An increase in power consumption increases heat. Heat also increases the power consumption. Thus, the less performant a processor becomes at last. The processor builders need something else to allow the computational race to proceed.
The first computers were huge and costly. They consume an enormous amount of power. Seymour Cray, one of the pioneers of supercomputing, built Cray-1, the first supercomputer, which contained many computing devices connected in one giant computer to reach unbelievable computation performance in $160$ MFLOPS ($10^6$ floating-point operations per second).
The lower environment also improved, and CPU developers came up with the multicore design of a computation device. Gluing everything together with the size limitation and multiple already existing CPU instructions in mind, the architecture from figure below appears.
In 1982, the Thinking Machines Corporation came up with a very interesting design. They connected 4096 16-core CPUs in one machine. IBM on another side created a device named «Cell» processor, connecting many high-speed «Stream Processors» together and using them from the general-purpose PC. «Cell» processor has a similar design as the first GPUs.

The combination of design solutions, described earlier, gave birth to the GPU (Graphics Processing Unit) architecture we’re using today in general-purpose GPU computations, computer graphics and video games.

Looking at the efficiency in parallel computation, many cores, and the optimizations GPU has, it’s natural that computational frameworks appeared. Nvidia created CUDA (Compute Unified Device Architecture) targeting their devices. Apple and ATI created OpenCL to unify the coverage, utilizing all possible multicore GPU solutions. Microsoft added Direct Compute functionality to DirectX. Not to mention combined solutions such as Open MP.
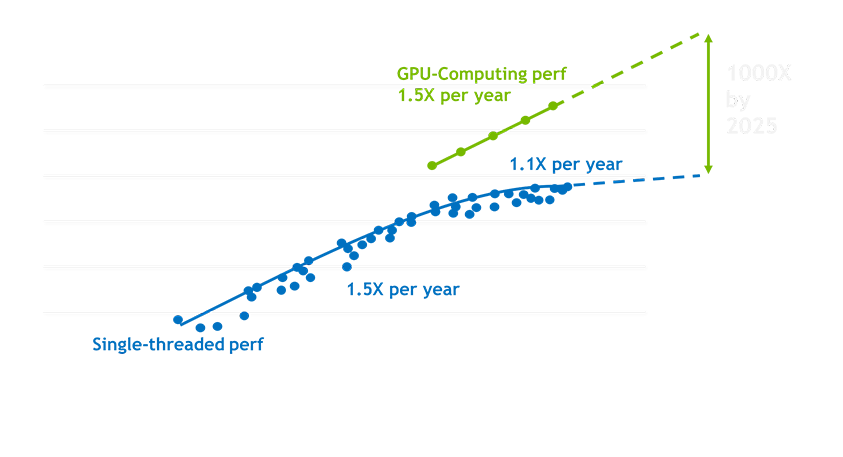
To conclude this, I’d like to mention the fact that the «CUDA Programming» book was written in 2012, but the area of computer devices is growing very fast, and the numbers, presented here are obsolete significantly. In the next figure, I’ve put some predictions of GPU computational growth made by NVIDIA. The CPU field doesn’t stay still as well, AMD released Rizen Threadripper with 96 CPU cores and 192 threads. The CPU is much more featured than the GPU in terms of diversity. So, let’s see how the market will grow.